2019. 7. 27. 00:54ㆍAI/Deep Learning
cs231n(Spring 2017) 강의를 정리합니다.
(본 포스팅은 cs231n 강의 Slide를 참고하여 작성하였습니다.)
강의 자료는 아래 링크를 참고하면 됩니다.
Youtube:https://youtu.be/vT1JzLTH4G4
Course Notes:http://cs231n.github.io/
In Lecture 4 we progress from linear classifiers to fully-connected neural networks. We introduce the backpropagation algorithm for computing gradients and briefly discuss connections between artificial neural networks and biological neural networks.

지난 시간에 각 클래스에 대한 score와 Loss를 구했습니다.
Overfitting은 training data에 편향되어 학습이 된 것을 말합니다.
training set에는 거의 완벽하게 성능을 보이지만 test set에는 제대로된 성능이 나오지 않습니다.
마치 문제집을 매번 풀던 것만 계속 풀어서 해당 문제집에 나온 문제는 잘 풀지만
새로운 문제가 주어졌을 때는 잘 풀지 못하는 것이라고 볼 수 있습니다.
우리가 원하는 것은 새로운 이미지가 주어졌을 때 어떤 이미지인지 잘 맞추기를 원합니다.
cs231n에서는 Overfitting을 방지하는 방법으로 Regularization을 소개했습니다.
(람다 값이 너무 작으면 Overfitting이 발생할 수 있습니다.)

Optimization은 Loss를 0에 가깝게 하는 hyperparameter를 찾는 것입니다.
gradient를 이용해 Loss가 작아지도록 합니다.
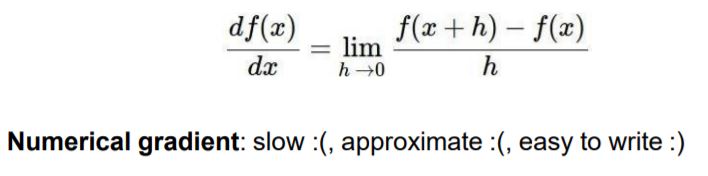
gradient는 위의 수식으로 풀어서 구하는 Numerical 방법이 있습니다.
보통 h는 0에 근사한 값을 사용하고, 보통 10e-4(:10^4)정도로 해서 gradient를 구합니다.
다른 방법으로는 Analytic 방법이 있습니다. 우리가 일반적으로 gradient를 구하는 방법으로
x^2 = 2x 같이 푸는 방법을 말합니다.
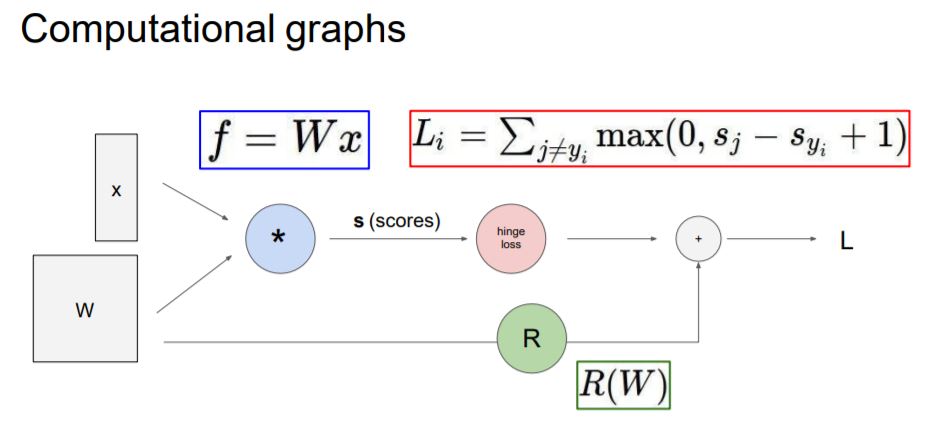
지금까지 내용의 Computational graphs를 보면 Wx에 대해서 scores를 구하고, Loss를 구한 다음
Regularization까지 해서 최종적으로 Loss를 구하는 과정의 graph로 표현이 됩니다.
이제부터는 Neural Networks에 대해서 배웁니다.

하나의 직선(f = Wx )으로는 위와 같은 문제들을 해결할 수 없었습니다.
위와 같은 Non-Linear한 문제를 해결하는 방법은 다음과 같이 층을 쌓는 것입니다.
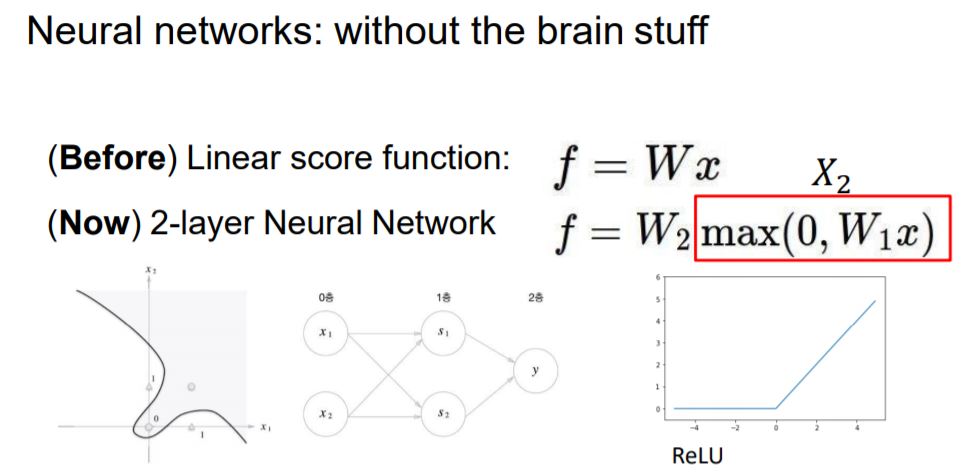
Layer을 쌓는 다는 것은 이전 Layer의 output이 다음 Layer의 weight와 곱해져 input으로 들어가면 됩니다.
2-Layer구조는 weight가 없는 층은 count하지 않아서 0층이고, 1층에는 0층의 output과 weight가 곱해져 input으로
들어오고, 1층의 output과 weight가 곱해져 2층으로 가서 최종 결과가 나오게 됩니다.
max 부분은 ReLU라는 Activation function이라고 보실 수 있습니다.

기존에 다뤘던 CIFAR-10을 이용해서 2-Layer를 적용하면 3072의 vector가 input으로 들어가 w1과 곱해져
h(hidden Layer)의 input으로 들어가고, 다시 h-Layer에서 100개의 output으로 나와 다시 w2와 곱해져 최종적으로 10개
의 클래스로 분류됩니다. 여기서 hidden Layer의 output 갯수는 hyperparamer입니다.

Layer는 계속 쌓아나갈 수 있습니다.
3-layer의 경우 hidden layer가 2개입니다.

Neural Networks는 인간의 뉴런을 연구하여 만들어졌습니다.
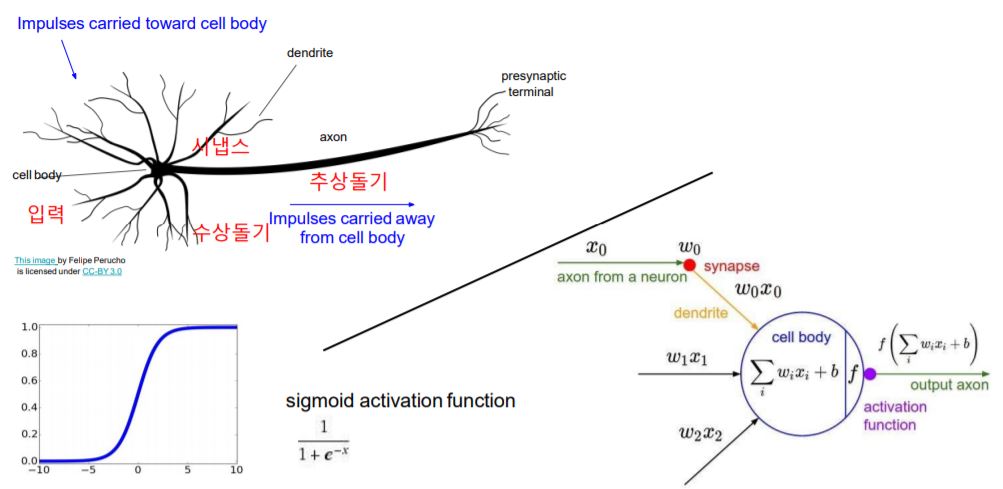
인간의 뉴런에서 자극이 들어오면 수상돌기에서 신호를 받아 추상돌기를 통해 신호를 전달합니다.
Neural Networks의 구조도 이와 비슷합니다.
입력 X(자극)이 들어오면 각 입력에 대한 강도(weight)가 곱해진 신호들의 합을 구합니다.
합에 대해서 Activation Function을 적용합니다.
임계값(Threshold)을 기준으로 신호들의 합을 Activation Function을 적용했을 때 output이 정해집니다.

Activation Function 몇 가지를 소개하고 있습니다.
Activation Function은 특정 무엇을 써야한다기 보다는 자신의 학습 모델에 적용할 때 다양하게 적용해보고,
가장 성능이 좋은 것을 선택하여 사용하면 됩니다.
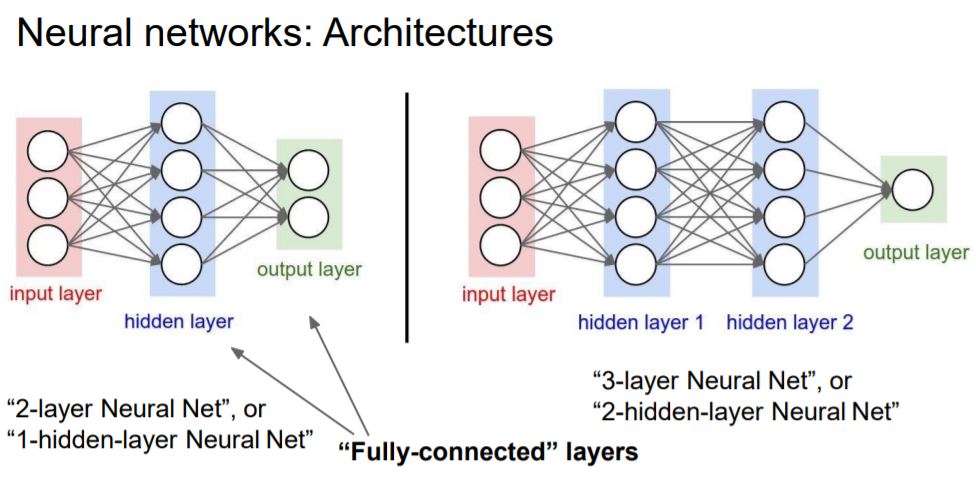
Neural Networks Architecture를 설명하고 있는데, 이전 Layer의 모든 node와 다음 Layer의 모든 node가 연결된 것을
Fully-connected Layer라고 부릅니다.
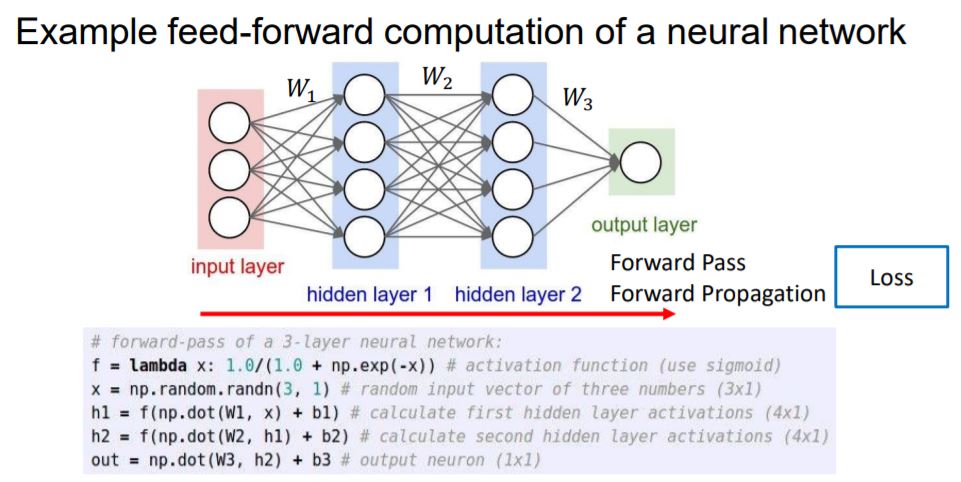
지금까지 배웠던 Loss를 구하는 과정을 Forward pass 또는 Forward propagation이라고 합니다.
그와 반대로 Loss쪽에서 input쪽으로 가면서 gradient를 구하는 것을 Backpropagation이라고 합니다.
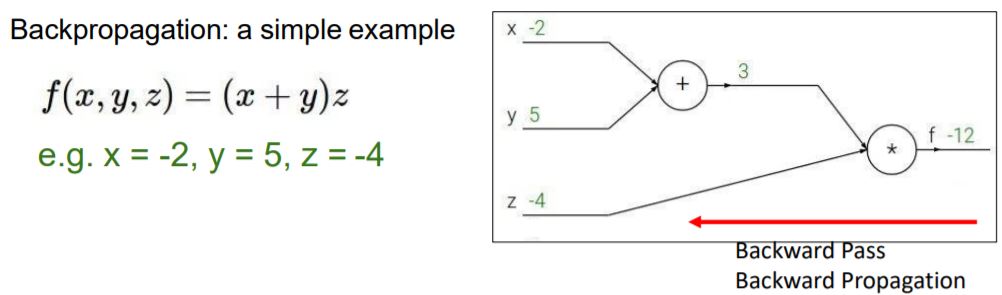
Backward propagation backpropagation은 Loss쪽에서 input쪽으로 gradient를 계산하면서
input이 Loss에 미치는 영향을 구할 수 있습니다.
그래서 최종적으로는 Loss를 0에 가깝게 Optimization을 해야하기 때문에
backpropagation을 통해서 input이 Loss을 크게 한다면 input값이 감소하도록 hyperparameter를 조정할 수 있고,
반대로 input이 Loss 값을 0보다 작게 한다면 input값이 증가하도록 hyperparameter를 조정할 수 있습니다.
Backpropagation하는 것을 간단한 예제를 통해 설명합니다.

x+y 의 결과를 q로 놓고, q*z를 f로 놓았습니다.
q = x+y, f=qz
각 변수에 대해서 편미분을 구한 식이 빨간 부분과 파란 부분입니다.
최종적으로 구하고자 하는 것은 x,y,z값의 f(loss)에 대한 편미분, 즉 x,y,z값이 f에 미치는 영향입니다.
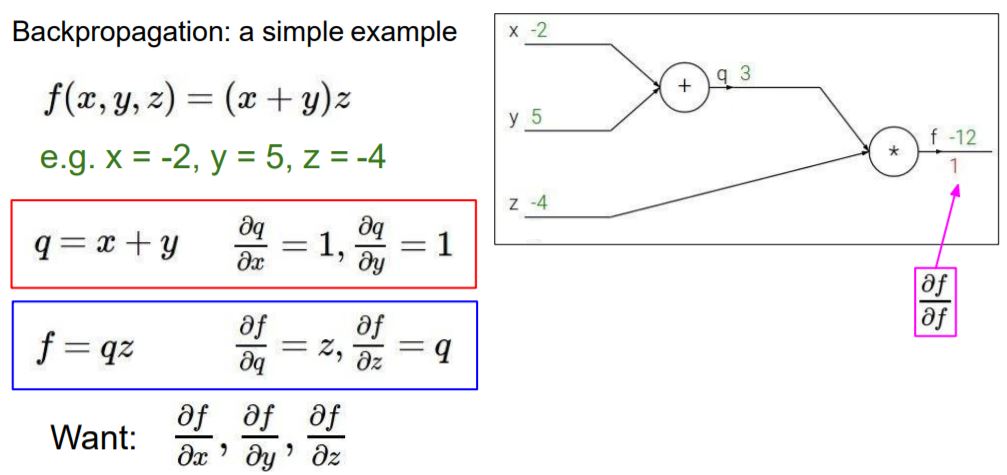
df/df는 자신의 대한 gradient이므로 1입니다. 즉, Loss의 gradient는 1입니다.

다음으로 df/dz를 구하면 파란색 부분에서 구해놨던 식에 의해서 q가 됩니다. 따라서 값은 3입니다.
즉, z값이 a만큼 변한다면 f값은 3a만큼 변한다고 할 수 있습니다.
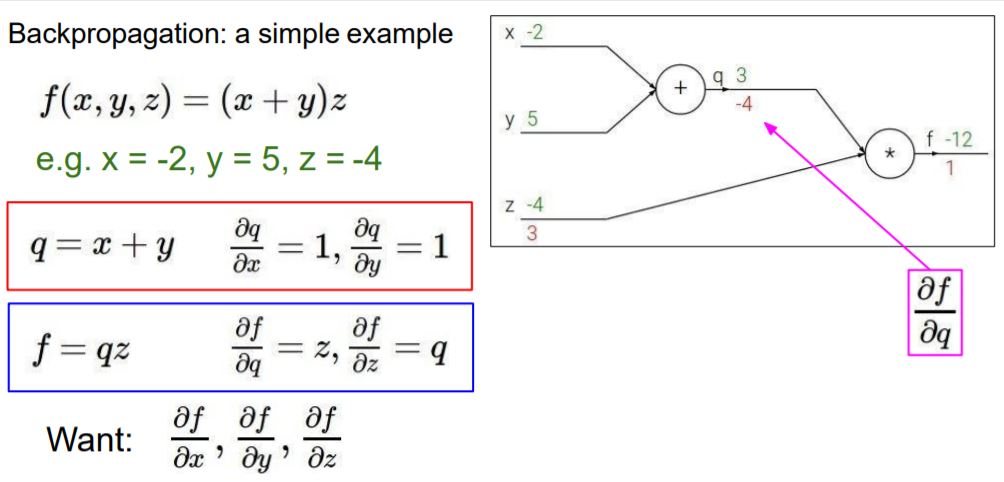
df/dq도 마찬가지로 파란색 부분에서 구해놨던 식에 의해서 z가 됩니다. 따라서 값은 -4입니다.
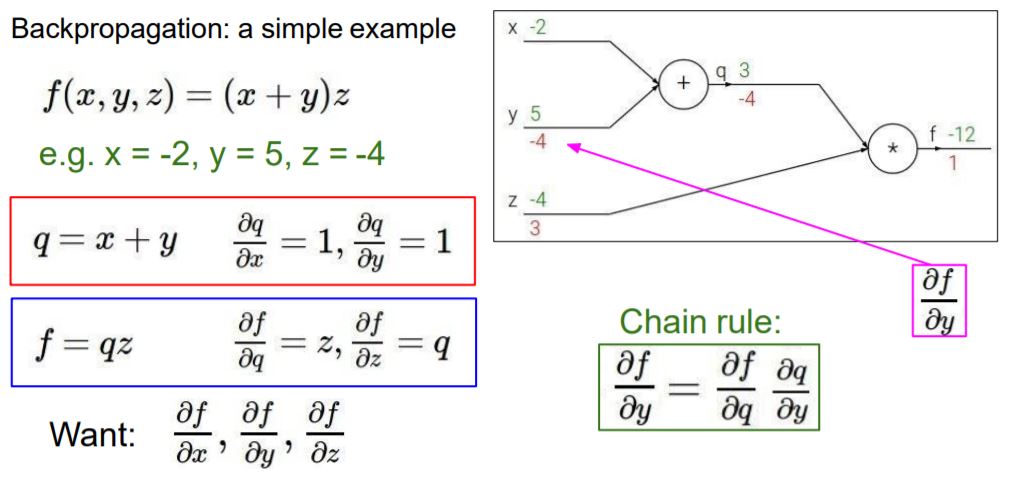
다음으로는 df/dy를 구해야하는데 df/dy는 Chain rule을 적용해서 구할 수 있습니다.
따라서 1*z가 되어 -4 값이 나옵니다.
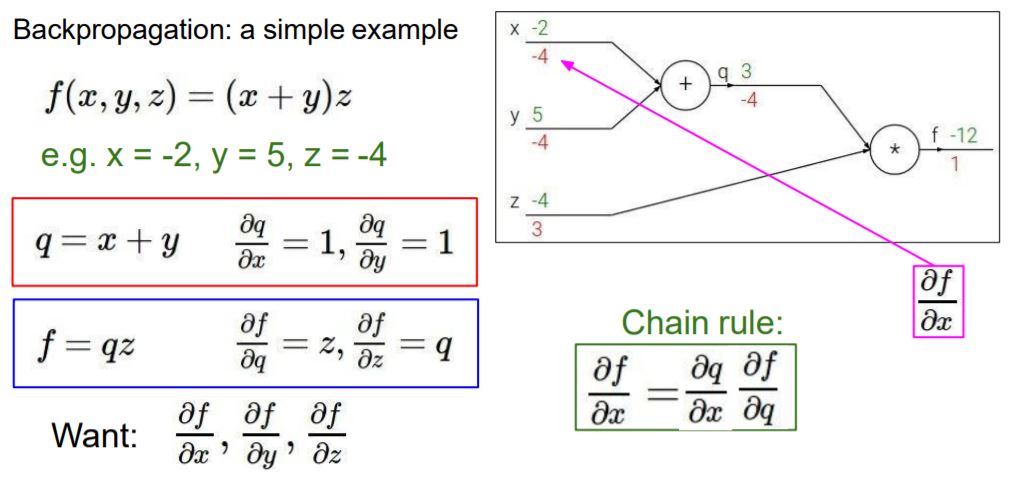
x값도 마찬가지로 Chain rule을 적용해서 구하면 1*z이므로 -4가 나옵니다.
이렇게 구하고자 하는 x, y, z의 f에 대한 gradient를 구했습니다.
정리하면 'x,y,z값이 a,b,c만큼 각각 변한다면 '-4a, -4b, 3c만큼 f에 영향을 준다.' 또는 '-4a, -4b, 3c만큼 f값이 변한다' 라고 할 수 있습니다.
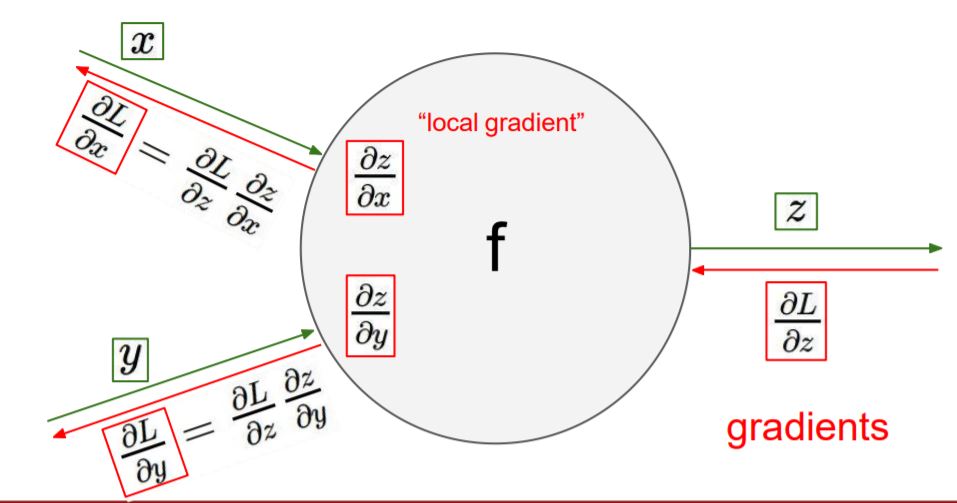
Forward propagation 과정에서 input에 대한 gradient(local gradient)를 구할 수 있고,
backpropagation 과정에서 gradients(global gradient)를 구할 수 있습니다.
Chain rule을 이용하면 (global)gradient * local gradient를 통해 input 값의 gradient를 구할 수 있습니다.

x, y 앞에 node가 있어도 마찬가지로 Chain rule을 이용해서 gradient를 구할 수 있습니다.
다른 예제 통해 backpropagation을 설명합니다.
이번 예제는 (w0x0 + w1x1 + w2)의 계산 값이 Sigmoid function에 input이 되어 계산되는 graph입니다.
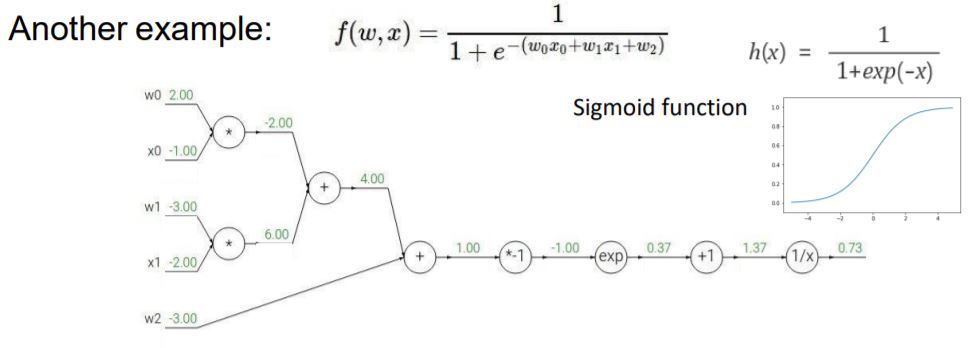
최종 값의 gradient는 앞서 배웠던 것처럼 1이 됩니다.
지금부터는 Chain rule을 적용하여 backpropagation을 구합니다.
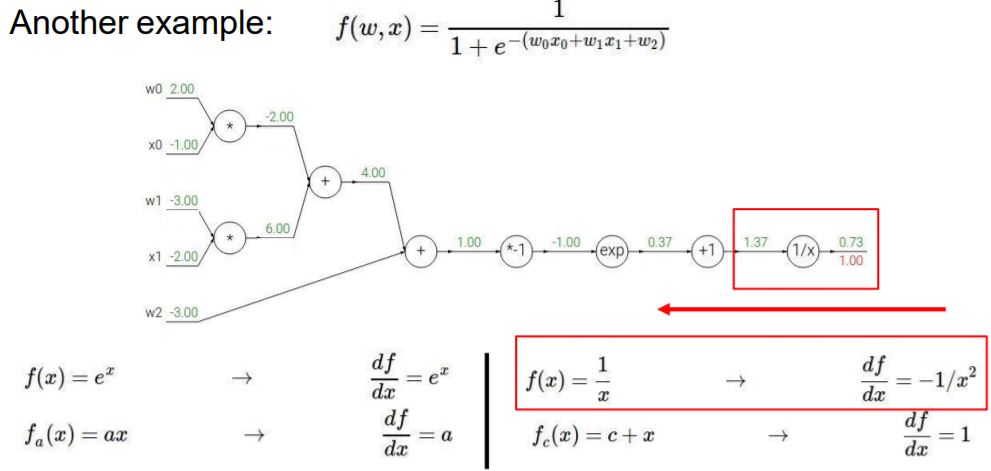
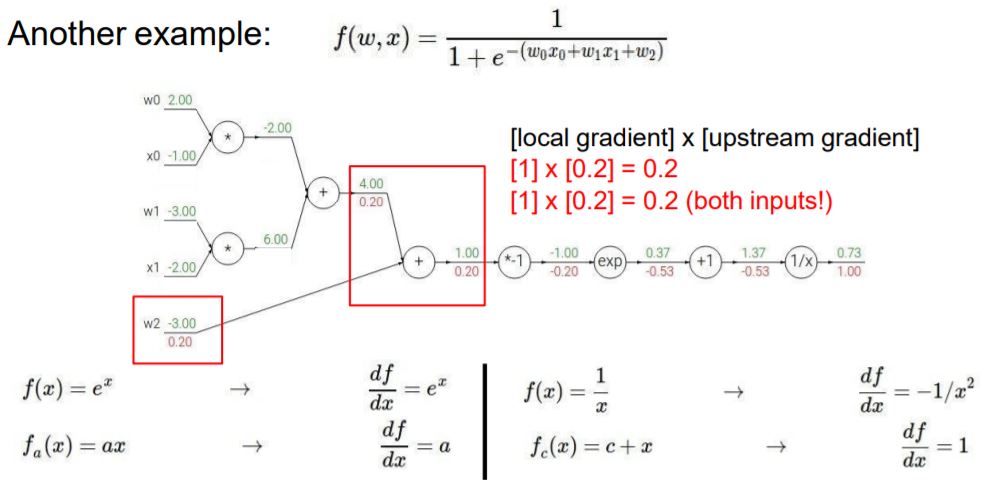
다음으로 1/x부분의 gradient는 -1/x^2이 되고, input으로는 1.37이 들어와서 연산이 됩니다.
global gradient는 1이 되고, Chain rule에 의해 두 값을 계산하면 다음과 같이 나옵니다.

같은 방법으로 -0.53값과 +1 노드를 계산하면 다음과 같습니다.
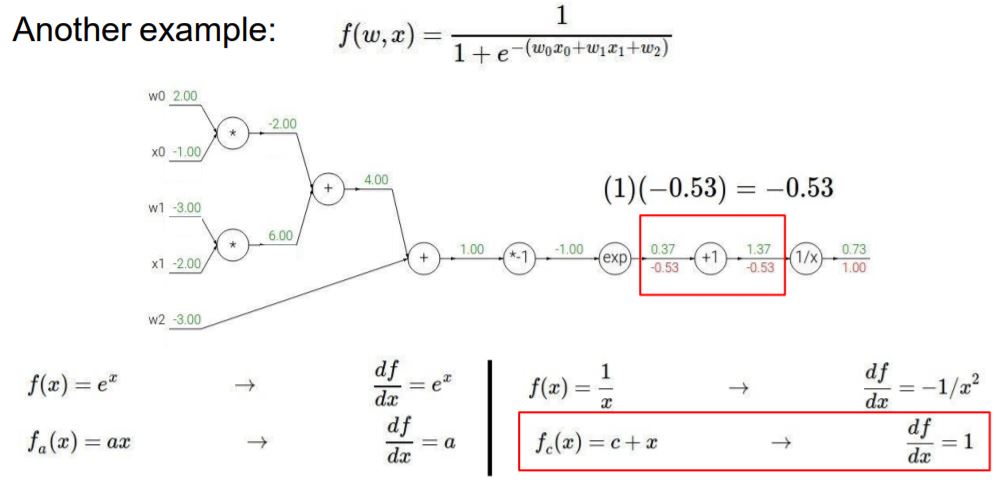
exp 노드에 대한 연산도 같은 방법으로 진행해줍니다.
단순하게 이전의 노드의 gradient와 다음 노드의 gradient 값을 곱하기만 해주면 됩니다.

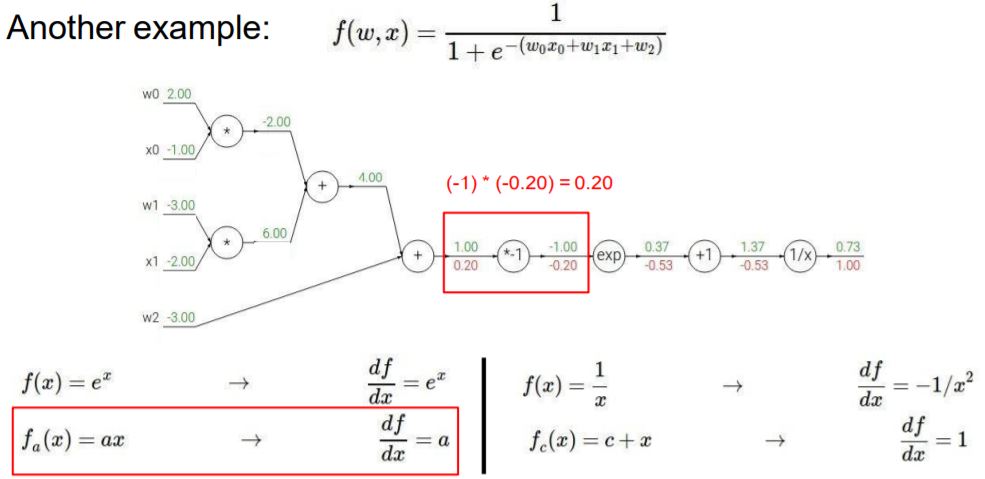
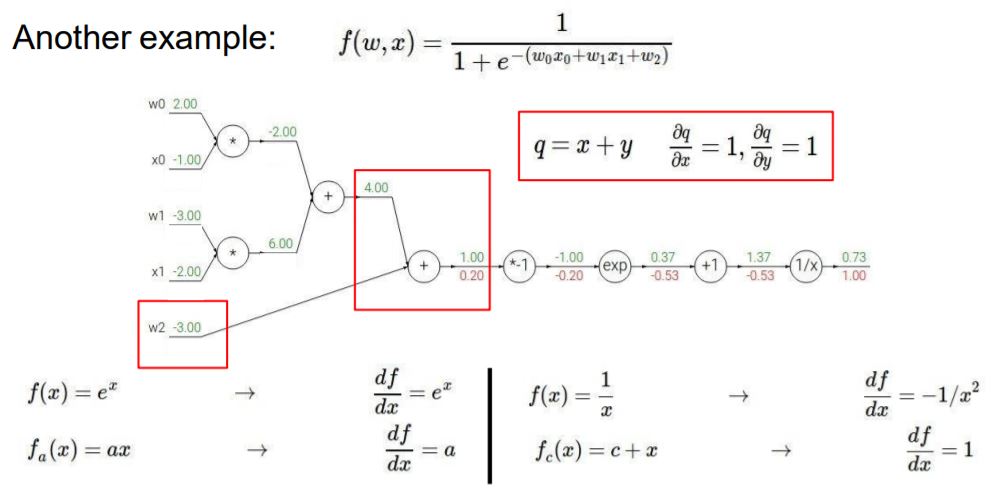
+ 노드는 앞서 배웠던 x+y 규칙과 같으니 gradient 값이 그대로 나가게 됩니다.
* 노드 또한 앞서 배운 규칙에 의해서 값이 구해집니다.


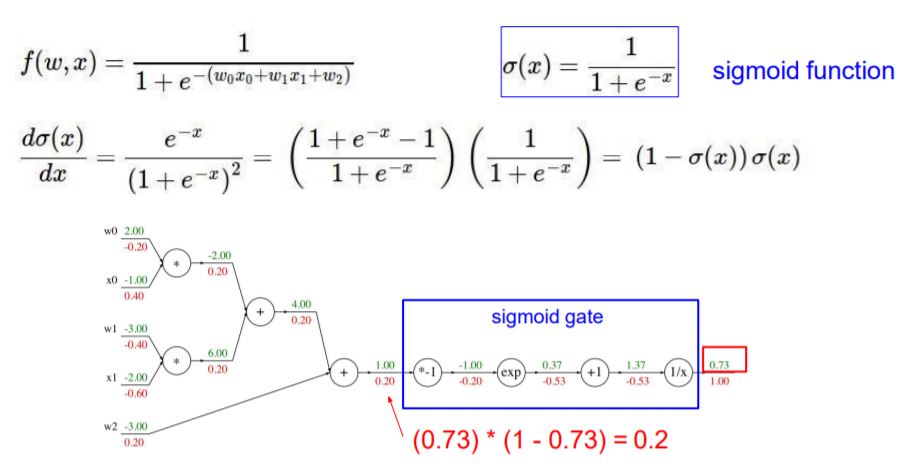
이번 예제는 어떤 input(w0x0 + w1x1 + w2)가 sigmoid의 input으로 들어간다고 했습니다.
그래서 다음과 같이 sigmoid에 대한 gradient를 구하면 *-1, exp, +1, 1/x 4단계를 거쳐 gradient를 구하지 않고,
sigmoid에 대한 gradient를 구해서 0.20이라는 값을 구할 수 있습니다.
연산 노드에 대한 패턴이 몇 가지 있습니다.
+노드의 경우 이전의 gradient 값이 그대로 나가게 되서 distributor라고 합니다.
* 노드의 경우 이전의 gradient 값과 반대쪽 input 값이 곱해져 gradient가 구해져서 switcher라고 합니다.
max 노드는 input 값들 중 가장 큰 값을 제외한 나머지는 gradient가 0이 됩니다.

만약 gradient가 복수 개가 들어있다면 모든 노드의 gradient를 더해주면 된다고 합니다.

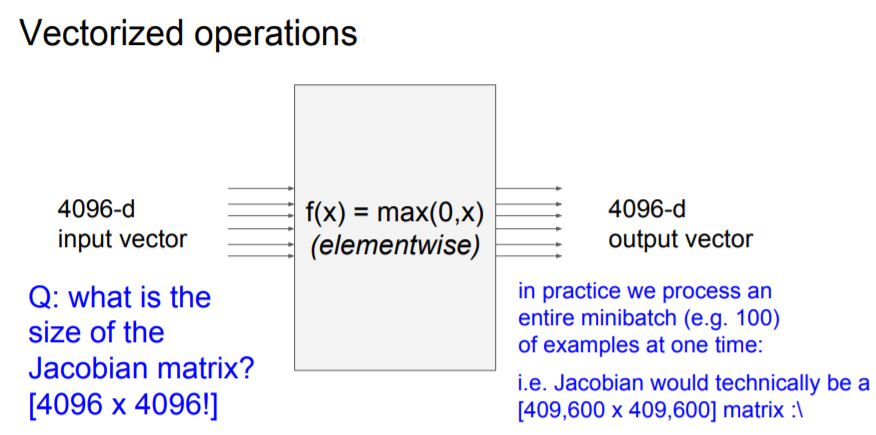
local gradient에 대한 값들을 Jacobian matrix를 이용해 미리 구해놓으면 연산이 편해진다고 합니다.
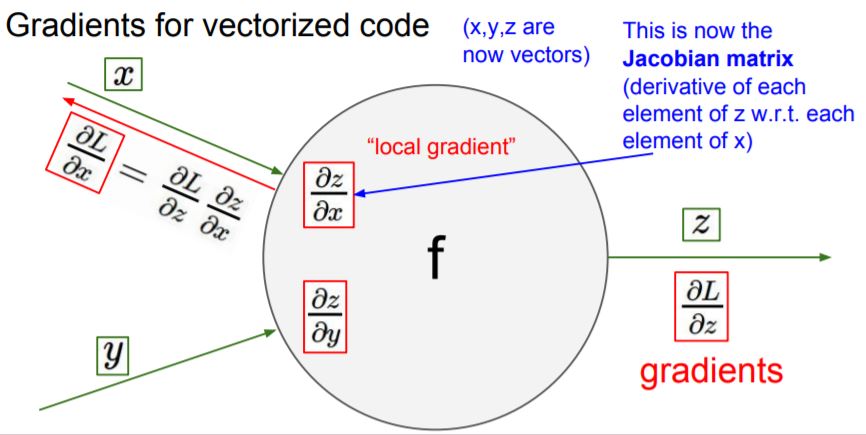
만약 input으로 4096 dimension의 data가 들어오고 4096 dimension의 output이 나간다면
Jacobian matrix는 4096x4096이 됩니다.
또한 mini-batch를 적용하면 batch 크기 배수 만큼의 Jacobian matrix가 된다고 합니다.
지금까지는 input 값이 단일 값이였다면 이번에는 input이 matrix일 때의 Forward pass와 backpropagation을 구합니다.
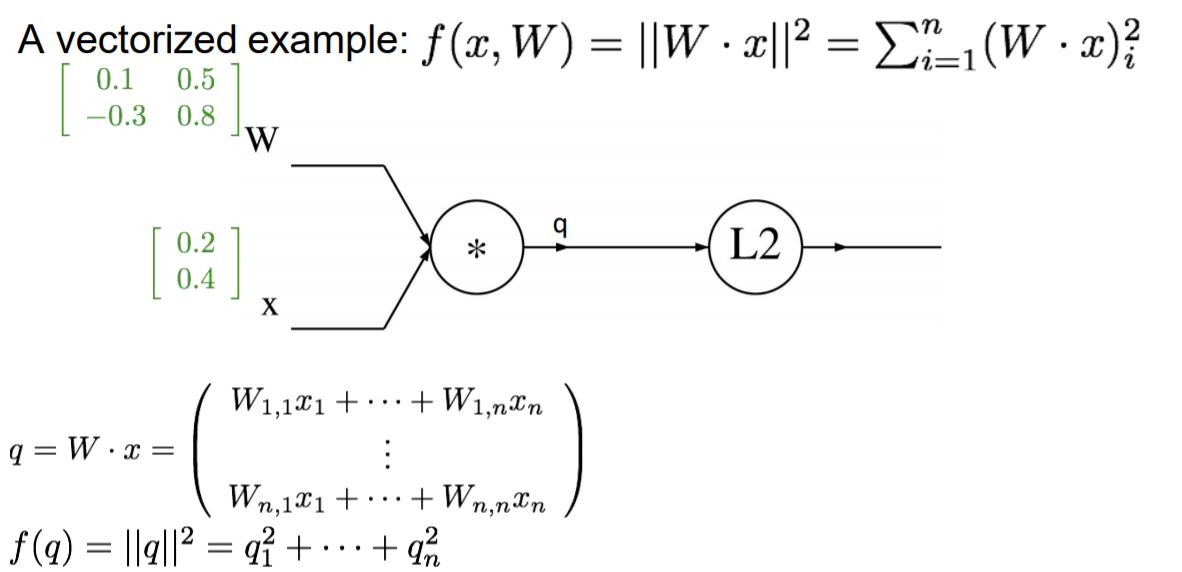
W, X(matrix이기 때문에 대문자로 표시하겠습니다.) WX는 구하면 q가 나옵니다. (2x2)●(2x1)=(2x1)
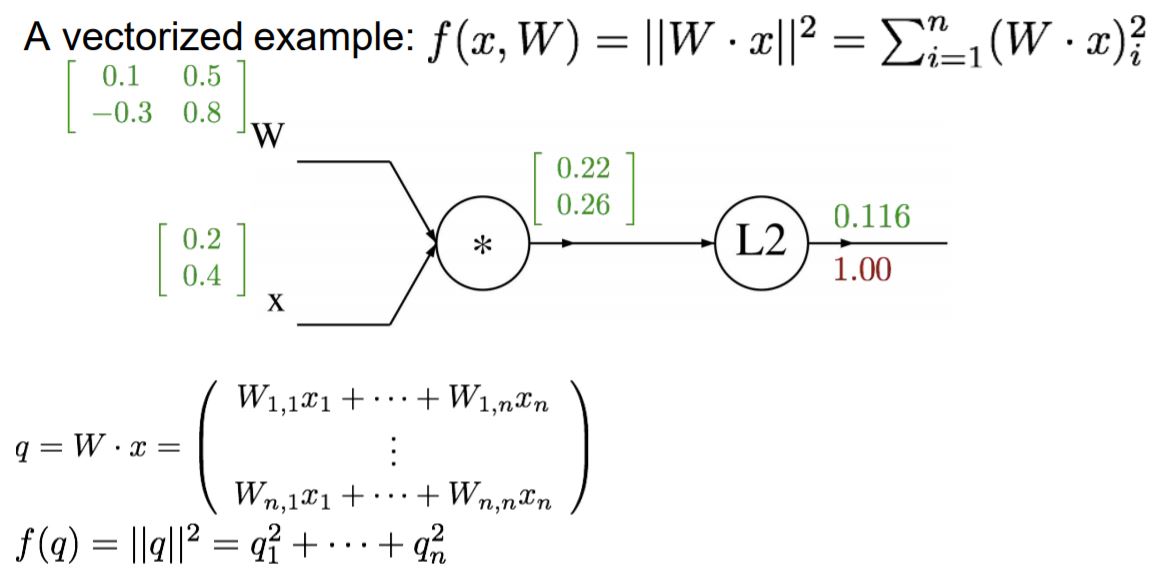
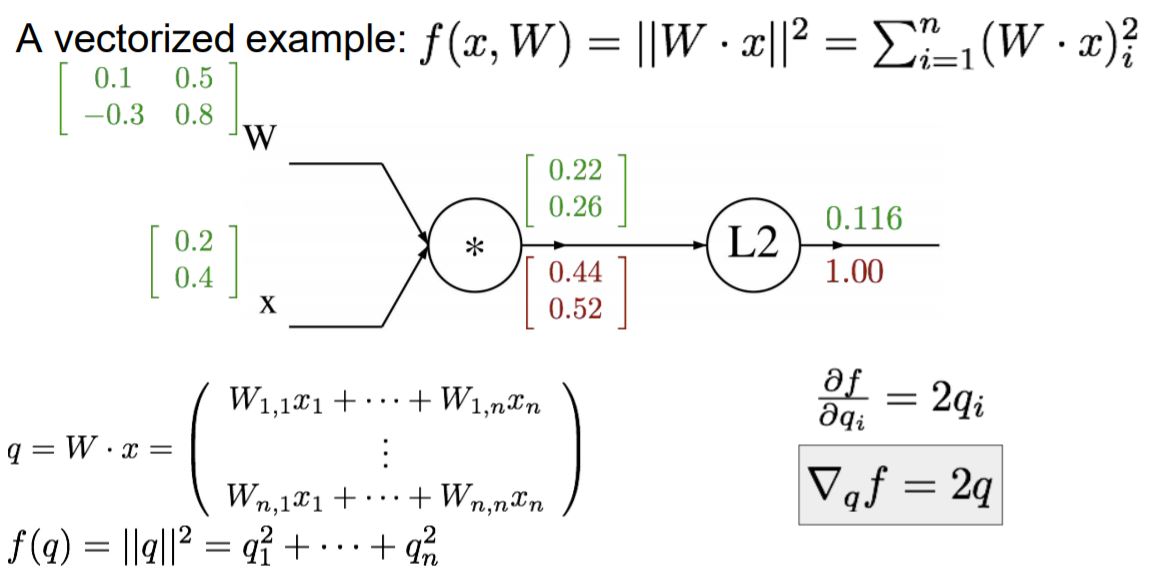
q^2 미분 값은 2q가 나옵니다. 따라서 df/dq 값이 위와 같이 나온 것입니다.

다음은 df/dw를 구해야하는데 Chain rule에 의해서 df/dq * dq/df가 됩니다.
df/dq는 앞서 구했던 2q이고, dq/dw는 (1 k=i) * Xj 이기 때문에 df/dw는 2qx가 됩니다.
q와 x가 2x1, 2x1이므로 하나를 Transpose를 해줘서 계산합니다.

빨간 부분은 항상 결과 값의 shape를 주의하라는 건데, 입력된 변수와 항상 같은 shape으로 나오는지 확인해야 합니다.
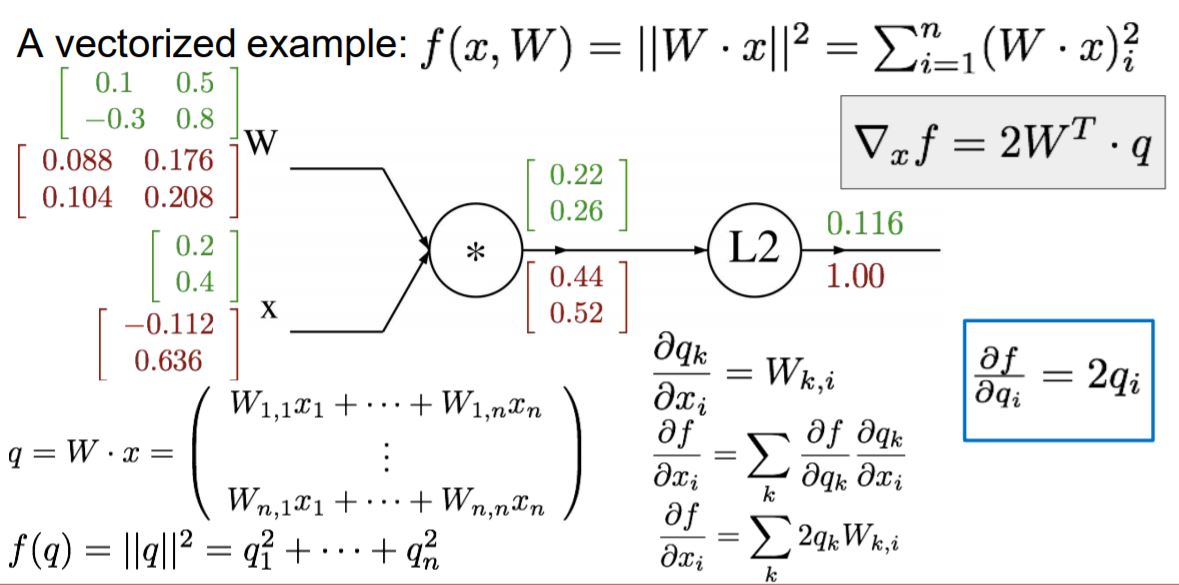
X값도 마찬가지로 gradient를 구하면 위와 같이 나옵니다.
matrix 연산이라 조금 복잡했지만 gradient와 chain rule을 적용해 푸는 것은 기존에 풀었던 것과 비슷합니다.

Lecture4까지 Forward를 통해서 input 값들에 대해서 Loss를 구했었고,
backpropagation을 통해서 각 input 값들이 Loss에 얼만큼의 영향을 주고 있는지를 구했습니다.
'AI > Deep Learning' 카테고리의 다른 글
| 신경망(2) 3층 신경망 구현 (0) | 2019.07.16 |
|---|---|
| 신경망(1) 활성화 함수 (0) | 2019.07.16 |
| 다층 퍼셉트론 (0) | 2019.07.16 |
| 단층 퍼셉트론 (0) | 2019.07.16 |
| [cs231n] Lecture3. Loss Functions and Optimization (0) | 2019.07.16 |