2019. 7. 16. 21:24ㆍAI/Deep Learning
지난 포스팅까지 AND, NAND, OR같이 간단한 문제를 단층 퍼셉트론으로 표현한 것과
XOR 같이 하나의 직선으로는 표현할 수 없는 문제를 다층 퍼셉트론으로 해결한 것을 배웠습니다.
이번 포스팅부터 배울 신경망의 구조는 다음과 같습니다.

신경망은 왼쪽부터 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)라고 합니다.
은닉층의 뉴런은 입력층이나 출력층과 달리 사람 눈에 보이지 않습니다.
지난 시간에 배웠던 수식 y = b + w1x1 + w2x2에서 y값이 0을 넘으면 1을 출력하고, 넘지 않으면 0을 출력하였는데요.
그림으로 보면 다음과 같습니다. 편향은 항상 입력 신호가 1이기 때문에 그림에서는 해당 뉴런을 회색으로 채워 다른 뉴런과 수
구별했습니다.

위 그림을 다음과 같은 수식으로 표현할 수 있습니다.

h(x)라는 함수가 나왔는데, h(x) 함수는 입력이 0을 넘으면 1을 반환하고, 그렇지 않으면 0을 반환합니다.
이 함수를 "활성화 함수"라고 합니다. 그래서 이 식은 다음과 같은 2개의 식으로 나눌 수 있습니다.
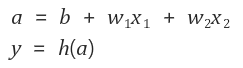
가중치가 달린 입력 신호와 편향의 총합을 계산하고, 이를 a라 합니다.
그리고 a를 함수 h()에 넣어 y를 출력하는 흐름입니다.
활성화 함수의 처리 과정

기존 뉴런의 원을 키우고, 그 안에 활성화 함수의 처리 과정을 명시적으로 그려 넣었습니다.
즉, 가중치 신호를 조합한 결과가 a라는 노드가 되고, 활성화 함수 h()를 통과하여 y라는 노드로 변환되는 과정이
분명하게 나타나 있습니다. (뉴런과 노드는 같은 의미)
*일반적으로 단순 퍼셉트론은 계단함수를 활성화 함수로 사용한 모델을 가리키고,
다층 퍼셉트론은 시그모이드 함수 등의 매끈한 활성화 함수를 사용하는 네트워크를 가리킵니다.
활성화 함수
<식 1>과 같은 활성화 함수는 임계값을 경계로 출력이 바뀌는데, 이런 함수를 계단 함수(step function)라 합니다.
그래서 '퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다'라고 할 수 있습니다.
활성화 함수는 계단 함수 외에도 다른 함수로 변경할 수 있습니다.
이것이 바로 신경망의 세계로 나아가는 열쇠입니다!
신경망에서 이용하는 활성화 함수를 살펴보겠습니다.
1. 계단 함수
|
1 2 3 |
def step_function(x): return np.array( x > 0, dtype=np.int)
|
입력으로 numpy array를 입력 받고, 각 원소 값을 비교해서 0보다 크면 1,
그렇지 않으면 0이 저장되는 array를 반환합니다.

2. 시그모이드 함수

시그모이드 함수는 신경망에서 자주 이용하는 활성화 함수입니다.
<식 3>은 시그모이드 함수의 식입니다.
|
1 2 |
def sigmoid(x): return 1 / (1 + np.exp(-x)) |

*시그모이드는 'S자 모양'이라는 뜻입니다. 계단 함수처럼 모양을 따서 이름을 지은 것입니다.
'S자 모양 함수'란 이름이 그 성질을 더 직관적으로 내비치지만, 시그모이드라는 이름이 실제 현장에서 많이 쓰이고,
소스 코드와 일관성 때문에 'S자 모양 함수'보다는 시그모이드라는 이름으로 쓰입니다.
3.시그모이드 함수와 계단 함수 비교
계단 함수와 시그모이드 함수의 그래프를 보면 먼저 느껴지는 것은 '매끄러움'의 차이입니다.
시그모이드 함수는 부드러운 곡선이며 입력에 따라 출력이 연속적으로 변화합니다.
계단 함수는 0을 경계로 출력이 갑자기 바뀌어버립니다.
시그모이드 함수의 이 매끈함이 신경망 학습에서 아주 중요한 역할을 하게 됩니다.
또한 계단 함수가 0과 1 중 하나만 반환하는 반면에 시그모이드 함수는 실수(0.731..., 0.880...등)를 돌려준다는 점도 다릅니다.
즉, 퍼셉트론에서는 뉴런 사이에 0 혹은 1이 흘렀다면, 신경망에서는 연속적인 실수가 흐릅니다.
4. 비선형 함수
계단 함수와 시그모이드 함수의 공통점은 둘 모두 비선형 함수입니다.
신경망에서는 활성화 함수로 비선형 함수를 사용해야 합니다.
그 이유는 선형 함수의 문제는 층을 아무리 깊게 해도 '은닉층이 없는 네트워크'로도 똑같은 기능을 할 수 있기 때문입니다.
예를 들어보면, h(x) = cx를 활성화 함수로 사용한 3층 네트워크는 y(x) = h(h(h(x)))가 되고,
계산을 하면 y(x) = c*c*c*x처럼 곱셈을 3번 하고, 결과적으로는 y(x) = c^3됩니다.
이는 y(x) = ax와 똑같은 식입니다. 즉, 은닉층이 없는 네트워크로 표현 할 수 있습니다.
5. ReLU 함수
시그모이드 함수를 신경망 분야에서 오래전부터 이용해왔으나, 최근에는 ReLU(Rectified Linear Unit, 렐루)함수를 주로 이용합니다.
코드와 그래프는 다음과 같습니다.
|
1 2 |
def relu(x): return np.maximum(0, x) |

ReLU함수의 수식은 다음과 같습니다.
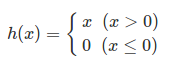
출처:
밑바닥부터 시작하는 딥러닝(한빛미디어, 사이토 고키 지음, 개앞 맵시 옮김)
그림 1~2, 식1: https://eehoeskrap.tistory.com/139
그림 3, 식4: https://simonjisu.github.io/deeplearning/2017/12/08/numpywithnn_2.html
'AI > Deep Learning' 카테고리의 다른 글
| [cs231n] Lecture 4. Introduction to Neural Networks (0) | 2019.07.27 |
|---|---|
| 신경망(2) 3층 신경망 구현 (0) | 2019.07.16 |
| 다층 퍼셉트론 (0) | 2019.07.16 |
| 단층 퍼셉트론 (0) | 2019.07.16 |
| [cs231n] Lecture3. Loss Functions and Optimization (0) | 2019.07.16 |